Welcome to NovaScope Documentation¶
Introduction¶
NovaScope is a Snakemake-based pipeline designed to process spatial transcriptomics data generated from Seq-Scope. It is specifically tailored for spatial arrays produced by the Illumina NovaSeq 6000 platform.
Functionality¶
The main purpose of NovaScope is to process Seq-Scope sequencing data from scratch to a spatial digital gene expression (SGE) matrix compatible with various single-cell and spatial analysis methods.
Additionally, it provides additional functionalities, including histology alignment with the SGE matrix, SGE filtering, SGE segmentation, and SGE reformatting. For more details about the main and additional functionalities, please refer to the Workflow Structure.
Characteristics¶
NovaScope features a modular and adaptable design, allowing users to tailor the pipeline to their specific requirements. The use of Snakemake ensures streamlined workflow management, reproducibility, and scalability.
NovaScope is designed to operate on Unix-based high-performance computing (HPC) platforms. It provides flexibility in deployment, allowing execution directly on local systems or through the SLURM workload manager.
Overview¶
NovaScope primarily consists of two steps, as illustrated in the figure below.
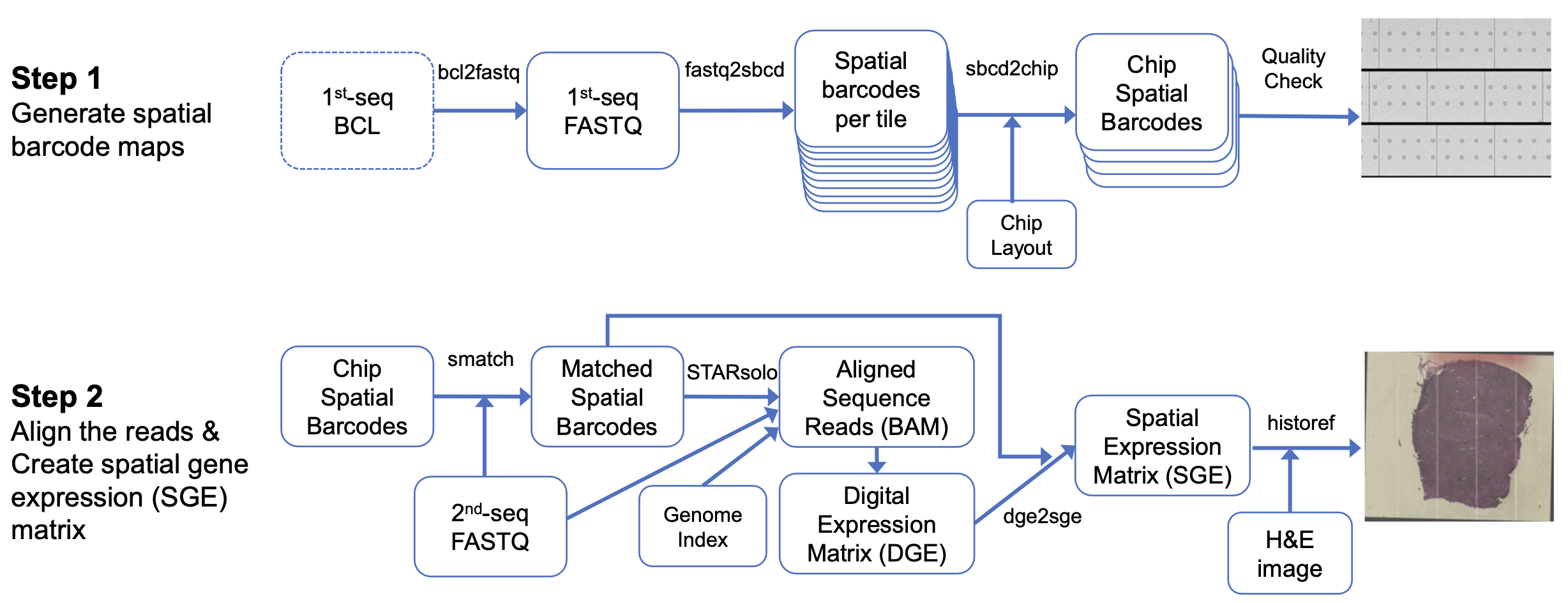
Figure 1: Overview of the NovaScope pipeline: Step 1 processes the 1st-seq FASTQ files to generate spatial barcode maps for each "Chip", a 10x6 array of tiles. Step 2 processes the 2nd-seq FASTQ files, aligns reads to the reference genome, and produces spatial gene expression at submicron resolution.
Links¶
-
The NovaScope protocol: DOI : 10.1038/s41596-024-01065-0.
-
An exemplary downstream analysis to analyze the SGE matrix generated by NovaScope is provided at NovaScope-exemplary-downstream-analysis.
-
Integrated Tools: NovaScope leverages several other tools from our lab to provide its full functionality. Please refer to the links below for more information on these integrated tools: